On Monday’s FOM class we discussed some homework problems, all of them dealing with sets. One question was raised by Alexis (I believe), and sounded something like this:
Which integers are in the set 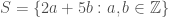
For starters, we should note that this set is, indeed, a subset of 



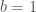

For the purposes of comparison, consider the set 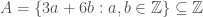
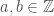


No such pattern appears to emerge when we work with the original set 

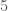
Indexed Sets
Another point of discussion yesterday concerned an indexed union. Although this is described quite well in our textbook (and you should re-read it for yourselves!), it seems like its worth exploring a bit further. In fact, I’ll even do this in well-organized sections (including the one containing this very paragraph). Note, however, that our focus will be on indexed unions, and you should keep in mind that we also care about indexed intersections and indexed other-operations.
A Finite Amount of Unions
Suppose I have five sets. “Sets of what?” you ask, to which I reply “Sets of anything!” Each individual set may be an interval of real numbers or a set of cats or a set of pictures or whatever. The important part is that they’re sets, and since I have five of them I’ll name them like this: 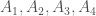

Then, of course, we can form the union of these sets, which we like to notate as
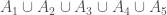
We can notate this new set more efficiently (i.e. using less horizontal space) by adopting the following notation:
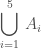
This notation should remind us of so-called “sigma summation” notation that one first encounters in calculus (often when learning about Riemann sums). However, the notation is a bit incomplete, at least technically. The reader has to infer that the expression “\latex i” runs through the first 
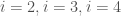
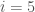

The expression above can be translated into the following English: “for every natural number between (and including) 1 and 5 we have a set, 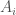


Example (1). Suppose 
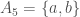

Two important observations to make about this (finite) indexed union. First, the index
Example (2). Here is an example, like your homework problems, where the description of the sets being unioned depend on the index 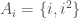
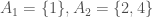

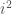

Example (3). Here is a strange-looking example, one that uses a bizarre (and rather arbitrary) index set. This example is important but silly, I should point out, but let’s discuss that after its all done. We’ll use the index set 







To write this out in any more meaningful or concrete way, I’d have to tell you what each set 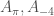
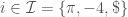
For the sake of completing this example, then, let’s go ahead and say that ![A_{\pi} = [-1/2, 1]](https://s0.wp.com/latex.php?latex=A_%7B%5Cpi%7D+%3D+%5B-1%2F2%2C+1%5D&bg=ffffff&fg=444444&s=0&c=20201002)

![A_{\$} = (-\infty, -1/2]](https://s0.wp.com/latex.php?latex=A_%7B%5C%24%7D+%3D+%28-%5Cinfty%2C+-1%2F2%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![\displaystyle \bigcup_{i\in\mathcal{I}} A_i = \bigcup_{i \in \{\pi, -4, \$\}} =[-1/2,1] \cup [0, \infty) \cup (-\infty, -1/2] = \mathbb{R}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbigcup_%7Bi%5Cin%5Cmathcal%7BI%7D%7D+A_i+%3D+%5Cbigcup_%7Bi+%5Cin+%5C%7B%5Cpi%2C+-4%2C+%5C%24%5C%7D%7D+%3D%5B-1%2F2%2C1%5D+%5Ccup+%5B0%2C+%5Cinfty%29+%5Ccup+%28-%5Cinfty%2C+-1%2F2%5D+%3D+%5Cmathbb%7BR%7D&bg=ffffff&fg=444444&s=0&c=20201002)
Infinitely Indexed
Of course, this process of union-ing over a finitely-indexed collection of sets works similarly for any sized index set, and, indeed, even for index sets that are not finite. Suppose we have a large collection of sets, one for each element in the counting or natural numbers 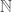


While certain flavors of philosophers and logicians may contest this process, we, as budding mathematicians, are perfectly comfortable with it. Union-ing together an infinite collection of sets results in a new set, one with elements that came from at least one of the indexed sets (it could have also come from multiple).
Again, it is important to note that the sets 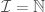
Example (4). Let’s use the sets 

In some ways this was a very silly example. After all, we didn’t have infinitely many distinct sets to union, we just unioned together the same three sets over and over again. Still, this example helps solidify our two main points, which are worth repeating here.
- The index parameter
- The index set (in this case
Example (5). Let us create an infinite family of sets each of which is described using the index 
![\displaystyle A_i = [0, 1/i] = \{x \in \mathbb{R} : 0 \leq x \leq 1/i\} \subseteq \mathbb{R}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+A_i+%3D+%5B0%2C+1%2Fi%5D+%3D+%5C%7Bx+%5Cin+%5Cmathbb%7BR%7D+%3A+0+%5Cleq+x+%5Cleq+1%2Fi%5C%7D+%5Csubseteq+%5Cmathbb%7BR%7D&bg=ffffff&fg=444444&s=0&c=20201002)
For example, here are a few of the (infinitely many) sets we’ll be union-ing together:
![A_1 = [0, 1] = \{x \in \mathbb{R} : 0 \leq x \leq 1\}, A_{20} = [0, 20] = \{x \in \mathbb{R} : 0 \leq x \leq 1/20\}](https://s0.wp.com/latex.php?latex=A_1+%3D+%5B0%2C+1%5D+%3D+%5C%7Bx+%5Cin+%5Cmathbb%7BR%7D+%3A+0+%5Cleq+x+%5Cleq+1%5C%7D%2C+A_%7B20%7D+%3D+%5B0%2C+20%5D+%3D+%5C%7Bx+%5Cin+%5Cmathbb%7BR%7D+%3A+0+%5Cleq+x+%5Cleq+1%2F20%5C%7D&bg=ffffff&fg=444444&s=0&c=20201002)
![A_{10000} = \left[0, \frac{1}{10000}\right].](https://s0.wp.com/latex.php?latex=A_%7B10000%7D+%3D+%5Cleft%5B0%2C+%5Cfrac%7B1%7D%7B10000%7D%5Cright%5D.&bg=ffffff&fg=444444&s=0&c=20201002)
In this example, the index
The index here is a natural number,
It is not too difficult o convince yourself that the larger 
![\displaystyle \bigcup_{i\in\mathbb{N}} A_i = [0, 1] \cup [0, 1/2] \cup [0, 1/3] \cup \cdots = [0, 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbigcup_%7Bi%5Cin%5Cmathbb%7BN%7D%7D+A_i+%3D+%5B0%2C+1%5D+%5Ccup+%5B0%2C+1%2F2%5D+%5Ccup+%5B0%2C+1%2F3%5D+%5Ccup+%5Ccdots+%3D+%5B0%2C+1%5D&bg=ffffff&fg=444444&s=0&c=20201002)
A Super-Infinite Union?
We now come to what I think is an especially tricky example, at least upon first glance. Although we are blessed / cursed with finite minds, thinking of an infinite collection of sets indexed by the counting numbers is not altogether too terrible. In Examples (4) and (5) above, we could have used the words
to describe the process by which we produced the new, big-unioned set. Another way to talk about it is to say that we performed a discretely infinite union; after all, the natural numbers can be thought of as a discrete (albeit infinite) set of points that go on forever.
What happens, though, when our index set is even more complicated? For instance, what happens when we have a collection of sets 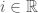
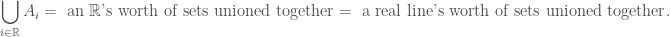
We could also describe it as a continuous union of infinitely many sets. The main issue we have with this union / indexing is that we cannot write out something like

since doing so excludes the real-number-indexed sets like 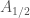

Example 6. If we use, for example, 
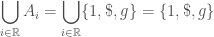
As in our examples that use finitely many indices and/or a natural-number’s worth of indices, the final set can be written out explicitly (and also without use of the index
Example 7. Let’s consider a real line’s worth of one-element sets 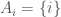
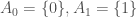


Example 8. In this example we’ll use a real line’s worth of interval-subsets of the real numbers, specifically setting ![A_i = [0, i^2]](https://s0.wp.com/latex.php?latex=A_i+%3D+%5B0%2C+i%5E2%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![\displaystyle \bigcup_{i\in\mathbb{R}} A_i = \bigcup_{i\in\mathbb{R}} [0,i^2] = [0, \infty)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbigcup_%7Bi%5Cin%5Cmathbb%7BR%7D%7D+A_i+%3D+%5Cbigcup_%7Bi%5Cin%5Cmathbb%7BR%7D%7D+%5B0%2Ci%5E2%5D+%3D+%5B0%2C+%5Cinfty%29&bg=ffffff&fg=444444&s=0&c=20201002)
You should be able to convince yourself that this is true by thinking about the facts that (1) 
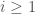
![[0, i^2] \subseteq [0, (i+1)^2]](https://s0.wp.com/latex.php?latex=%5B0%2C+i%5E2%5D+%5Csubseteq+%5B0%2C+%28i%2B1%29%5E2%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Example 9. We can, of course, also use not an entire real-line’s worth of sets, but, say, an intervals worth of sets. If we use ![\mathcal{I} = [0, 1] = \{x \in \mathbb{R} : 0 \leq x \leq 1\}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BI%7D+%3D+%5B0%2C+1%5D+%3D+%5C%7Bx+%5Cin+%5Cmathbb%7BR%7D+%3A+0+%5Cleq+x+%5Cleq+1%5C%7D&bg=ffffff&fg=444444&s=0&c=20201002)
![\displaystyle \bigcup_{i \in [0,1]} A_i](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbigcup_%7Bi+%5Cin+%5B0%2C1%5D%7D+A_i&bg=ffffff&fg=444444&s=0&c=20201002)
For example, if we use the sets from Example 8 so that each
![\displaystyle \bigcup_{i\in[0,1]} A_i = [0, 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbigcup_%7Bi%5Cin%5B0%2C1%5D%7D+A_i+%3D+%5B0%2C+1%5D&bg=ffffff&fg=444444&s=0&c=20201002)
 it is possible to choose
it is possible to choose  points on a circle in such a way that if you connect every pair of points with straight line segments, the circle will be divided into
points on a circle in such a way that if you connect every pair of points with straight line segments, the circle will be divided into 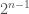 regions.
regions. be the product of the first
be the product of the first 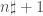 is prime.
is prime.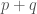 , where
, where  and
and  are both prime numbers.
are both prime numbers.
 is any set (it can be a set of familiar objects, like real numbers, it can be the empty set, or it can even be a set of something silly and/or pointless).
is any set (it can be a set of familiar objects, like real numbers, it can be the empty set, or it can even be a set of something silly and/or pointless). ? If so, why? If not, why not? What does a proof for your answer look like?
? If so, why? If not, why not? What does a proof for your answer look like?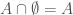 ? If so, why? If not, why not? What does a proof for your answer look like?
? If so, why? If not, why not? What does a proof for your answer look like? ? Using our definition, we know that
? Using our definition, we know that 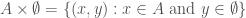 . Of course, this means that the element
. Of course, this means that the element  doesn’t exist, and so we might instead write
doesn’t exist, and so we might instead write  .
.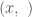 as “nothing” we are no longer talking about an ordered pair! An ordered pair is, by definition, a pair of things that exist. Hence, there are no ordered pairs in the set
as “nothing” we are no longer talking about an ordered pair! An ordered pair is, by definition, a pair of things that exist. Hence, there are no ordered pairs in the set  Ready for it? Have you figured it out yet?? That’s right!
Ready for it? Have you figured it out yet?? That’s right!  !
! (that is, two sets that each have finite cardinality), then the cardinality of their cross-product should be
(that is, two sets that each have finite cardinality), then the cardinality of their cross-product should be 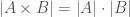 . Assuming this is true, and letting
. Assuming this is true, and letting 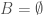 what do we learn about the cardinality of
what do we learn about the cardinality of 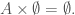
 bonus points, if not more.
bonus points, if not more.




 that compares the number of petals to the curve’s turning number depends transcendentally on the maximum radial value and can only take values in the interval
that compares the number of petals to the curve’s turning number depends transcendentally on the maximum radial value and can only take values in the interval ![\left[\frac{1}{2},\frac{1}{\sqrt{2}}\right].](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cfrac%7B1%7D%7B2%7D%2C%5Cfrac%7B1%7D%7B%5Csqrt%7B2%7D%7D%5Cright%5D.&bg=ffffff&fg=444444&s=0&c=20201002) Indeed, such a reader would be correct.
Indeed, such a reader would be correct. the support function of
the support function of  is given by
is given by  where
where  is a unit normal. For planar curves the support function is related to (signed) curvature via the equation
is a unit normal. For planar curves the support function is related to (signed) curvature via the equation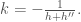
 must be locally convex so that it can be regularly parameterized by its unit normal
must be locally convex so that it can be regularly parameterized by its unit normal 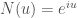 . Assuming this and after applying a suitable rescaling, one discovers that
. Assuming this and after applying a suitable rescaling, one discovers that 
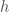 must satisfy the more general partial differential equation
must satisfy the more general partial differential equation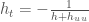
 with
with  parameterizing the unit normal and
parameterizing the unit normal and  representing time.
representing time. also shows up when seeking “weighted geodesics” (more specifically, but admittedly less clear, “Gaussian-weighted geodesics”). Indeed, the quantity
also shows up when seeking “weighted geodesics” (more specifically, but admittedly less clear, “Gaussian-weighted geodesics”). Indeed, the quantity 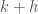 is known as “weighted curvature.”
is known as “weighted curvature.”
 (it behooves me to mention that the
(it behooves me to mention that the 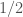 factor is inconsequential; it corresponds to my choice of rescaling).
factor is inconsequential; it corresponds to my choice of rescaling).

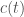 is a smooth function. Evaluating this expression at
is a smooth function. Evaluating this expression at 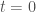 , dotting with
, dotting with 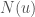 , and letting
, and letting  produces the equation
produces the equation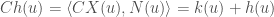
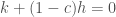 . When
. When  this corresponds to old shrinkers, and when
this corresponds to old shrinkers, and when 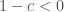 we have an old expander. In either event, the game is over. We’ve “looped” back to our starting point.
we have an old expander. In either event, the game is over. We’ve “looped” back to our starting point.